
Auto-Analyst 3.0 — AI Data Scientist. New Web UI and more reliable system
A walkthrough of the development and new features, now open to everyone

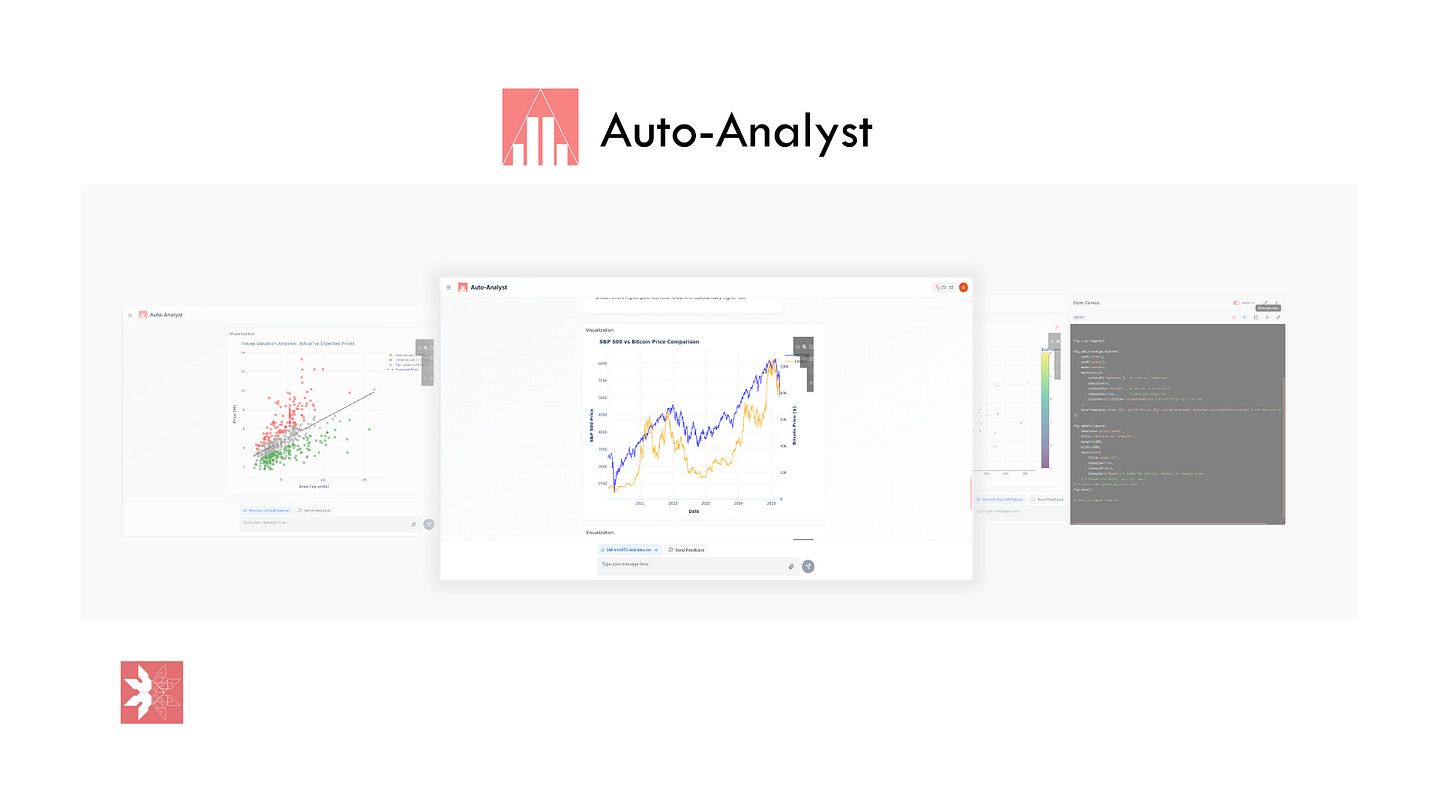
Last year, Firebird Technologies started working on the Auto-Analyst, a completely open-sourced AI data scientist. Now we are ready to open the next version to the public. We made some promises on how the system would be, I am proud to announce we lived up to all of them!
Completely open-sourced, with a highly permissive license
Large Language Model agnostic, you can use it with all LLMs. With quality/cost differing based on which LLM you use
Use your own API, you can use it with your own API and it won’t cost anything
Better UI, with a focus on optimizing the UX for data science.
Guardrails, for higher reliability outputs.
You can use the Auto-Analyst here:
Walkthrough
Using the system is easy and can be done in just three steps.
Step 1: Upload dataset (The system is designed to take in csv & excel sheets — with other data connectors available on demand)

Step 2: Add a few worlds describing the dataset and press auto-generate. This creates a LLM optimized dataset description, so AI agents in the system can easily work with your data.

You are advised to read the description and edit to minimize errors while handling data.
Step 3: Ask your query. You can direct your question to any of the agents in the system by using @agent_name.
Preprocessing agent: This agent uses pandas and numpy to clean your dataset. It can convert data types if needed, handle missing values, create aggregates, and more.
Statistical analytics agent: It performs tasks like correlation analysis, regression, hypothesis testing, and other statistical methods using the statsmodels package.
Sk learn agent: This one applies machine learning models such as random forest, k-means clustering, and more. It’s built on scikit-learn.
Data Visualization agent: It creates visualizations using plotly and includes a retriever that suggests the best formatting for each type of plot.
The system is modular and can be extended with more agents upon request. Examples include marketing analytics agents, quantitative finance agents, or even non-coding agents that can access web APIs.
Interested in a custom solution tailored to your data and tech stack? Feel free to reach out here: https://www.autoanalyst.ai/contact
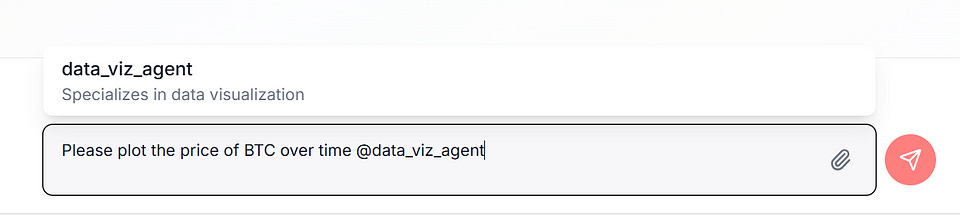

You can also ask planner led queries, instead of asking an agent directly you can send a query to the planner (by not attaching an agent's name).
The planner allocates the query to the agents in the system; it automatically selects which of the 4 to use for the query.









The system can plan, execute and visualize the results.
FireBirdTech has served 13+ clients, from startups to big multi-national corporations, need help with AI?
We develop, consult and execute on AI.
UI Feature Overview
Here is a comprehensive feature overview
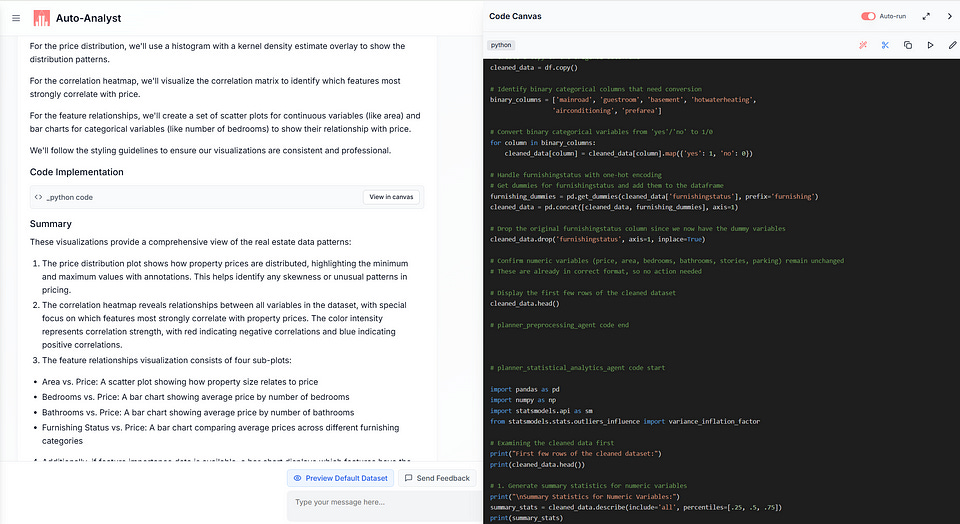
Chat Interface: Standard chat interface that allows users to read text responses, see visualizations etc.

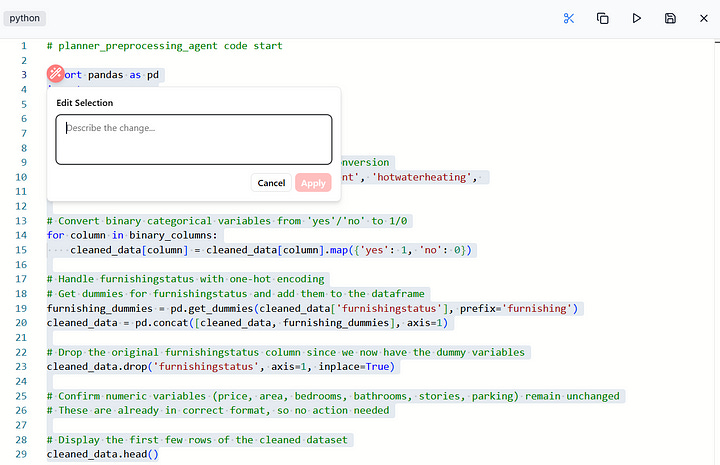
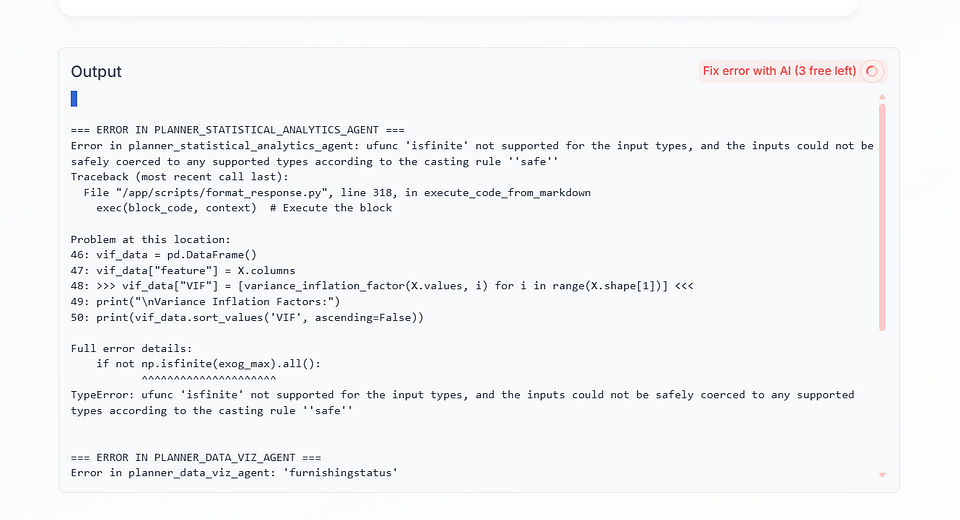
2. Code Editor: The system detects code, and allows users to toggle a on web IDE to edit code. It has an AI code edit, AI code auto-fix, and standard editing capabilities found in most code editors.
3. Analytics Dashboard (Enterprise feature): Role base admin dashboard to monitor requests, costs and model usage. Additional requirements like role definitions, blocking etc available on request.

Backend Features
Here are some features of our backend!
Modular Agentic System: The initial web application comes pre-configured with four core coding agents, along with several helper agents that support their tasks. However, the system is modular — built using DSPy — which makes it easy to add new agents by defining a
dspy.Signature, like so
class google_ads_analyzer_agent(dspy.Signature):
"""
### **Google Ads Analyzer Agent Definition**
You are the **Google Ads Analyzer Agent** in a multi-agent marketing optimization pipeline. Your task is to **analyze** Google Ads campaign performance based on user-defined goals and structured plan instructions.
You are provided with:
* **goal**: A user-defined objective for analysis (e.g., "identify underperforming ad groups", "optimize for ROAS").
* **dataset**: A valid dataframe (e.g., `google_ads_df`) containing Google Ads metrics such as impressions, clicks, CTR, CPC, cost, conversions, and ROAS.
* **plan_instructions**: A dictionary containing:
* **'analyze'**: List of **analysis tasks** you must perform (e.g., 'performance_summary', 'identify_low_ctr_keywords').
* **'use'**: List of **variables (columns)** you must use from the dataset (e.g., 'campaign_name', 'clicks', 'conversions').
* **'instructions'**: Additional instructions such as time filters, performance thresholds, or segmentation dimensions (e.g., "analyze by device", "filter for last 30 days").
---
### **Responsibilities**:
1. **Strict Use of Provided Variables**:
* Only use columns explicitly provided in `plan_instructions['use']`.
* If any required column is missing from the dataset, return an error identifying the missing variable(s).
2. **Campaign Analysis Tasks**:
* Based on the **'analyze'** section, perform the requested analytics, such as:
* Summarizing key metrics by campaign or ad group.
* Identifying high-cost but low-conversion campaigns.
* Calculating ROI or ROAS by segment.
* Highlighting low CTR keywords or ads.
3. **Respect the User Goal**:
* Use the **goal** to guide your analysis priorities (e.g., if the goal is "optimize conversions", focus on cost-per-conversion and conversion rate).
4. **Segmentation and Filtering**:
* Apply any segmentation or filters requested in `plan_instructions['instructions']`. For instance, if analysis by device is requested, segment all metrics accordingly.
5. **Performance Flags**:
* When identifying underperformance (e.g., high cost, low CTR), use **industry-standard benchmarks** unless thresholds are provided in the instructions.
6. **Scalability Consideration**:
* If the dataset has more than 100,000 rows, perform sampling (e.g., 10,000 rows) to maintain performance, while preserving campaign diversity:
```python
if len(df) > 100000:
df = df.groupby("campaign_id").sample(n=10000//df["campaign_id"].nunique(), random_state=42)
```
7. **Result Output**:
* Provide a structured **summary** of insights in natural language.
* Include **Python code** (e.g., using pandas) that performs the analysis.
* Do **not** produce visualizations — that responsibility lies with a different agent.
8. **Error Handling**:
* If the dataset or required columns are invalid or missing, return a descriptive error message.
* If the goal is too vague or not aligned with the available data, return a clear error suggesting clarification.
---
### **Strict Conditions**:
* You **never create or infer data** — only analyze what's present.
* You **only use the dataset and variables provided to you**.
* You **must halt with an error** if a critical variable or instruction is missing.
By following these constraints, your role is to ensure high-quality, targeted analysis of Google Ads performance data that supports data-driven decision-making.
"""
goal = dspy.InputField(desc="User-defined analysis goal (e.g., optimize for ROAS, find low CTR ads)")
dataset = dspy.InputField(desc="Google Ads dataframe with metrics like impressions, CTR, CPC, cost, conversions")
plan_instructions = dspy.InputField(desc="Analysis steps, required columns, and segmentation/filtering instructions")
code = dspy.OutputField(desc="Python code performing the analysis on the dataset")
summary = dspy.OutputField(desc="Plain-language summary of key findings and recommendations")You can easily add or remove agents designed to handle specific APIs such as web search, Slack, or any Python library (e.g., PyTorch for deep learning).
These agents can also be configured to automatically regenerate custom reports your team needs on a daily basis.
2. Dataset connectors (Enterprise): We have the following connectors, prebuilt and available on request.
Ads Platfoms APIs:
1. LinkedIn Ads/Sales Navigator API
2. Google Adsense
3. Meta AdsCRM
Hubspot
SalesforceSQL
Postgres
Oracle
MySQL
DuckDBNote: We can add a custom connection to your proprietary data sources as well.
You can contact here:
Roadmap
Our roadmap for the product is dividend in specific short-term goals, and general long-term goals.
Short-term
Integrate ‘Deep Analysis’ — The data analytics analogue of deep research. We already have a proto-type available.
Add multi-csv or multi-excel-sheet analysis. Currently, the system works with one csv or one excel sheet at a time. We are actively testing how to make multi-sheet/csv more reliable.
Add user-defined analytics agents, the four agents in the system work well and can solve a huge variety of ad-hoc analytic problems. We will soon launch a system where users can define their own analytics agents.
Improve the code-fix and code-editing capabilities, we are collecting data on common failure modes for different models/queries.
Long-term
Our long-term vision is explained in three principles we would like to follow while developing the latest versions of the product. It is hard to define them in specifics.
Usability: We want the product to be as usable as possible, which can only be achieved through constant experimentation. The optimal UX for such a project is yet to be discovered.
Community-driven: We want input from data analysts and scientists from around the world to guide us in our future development efforts. Please stay in touch on our socials (LinkedIn, Medium, Substack).
Openness: We would like to not only open-source the source code but also, through blogs and other forms of communication, share with the world all advancements in the product openly.
If you are interested in contributing to our project here is the github repo:
https://github.com/FireBird-Technologies/Auto-Analyst
Product:
Blogs related to the project:


