
I started reviewing AI tools and writing about them a couple of months ago. This style of blog has been both successful and fun. Readers have really enjoyed my perspective and found it insightful.
Cursor was one of the first coding agents to gain mainstream popularity after Gavin. Anysphere, the company behind Cursor, is the fastest company to reach both $100 million ARR and $1 billion ARR. Needless to say, the tool is extremely popular and useful.
Coding agents have really heated up in the last couple of months, with Anthropic and OpenAI both launching their own AI coding assistants. That makes this the perfect time to share what I think about them as someone who has been building AI apps for over two years.
Watch the video version of this review:
Video made using:
Overview
Lets start with a general and quick overview of what capabalities cursor really has. It is a customized version of the OSS IDE VSCode, popular among developers.
Tab
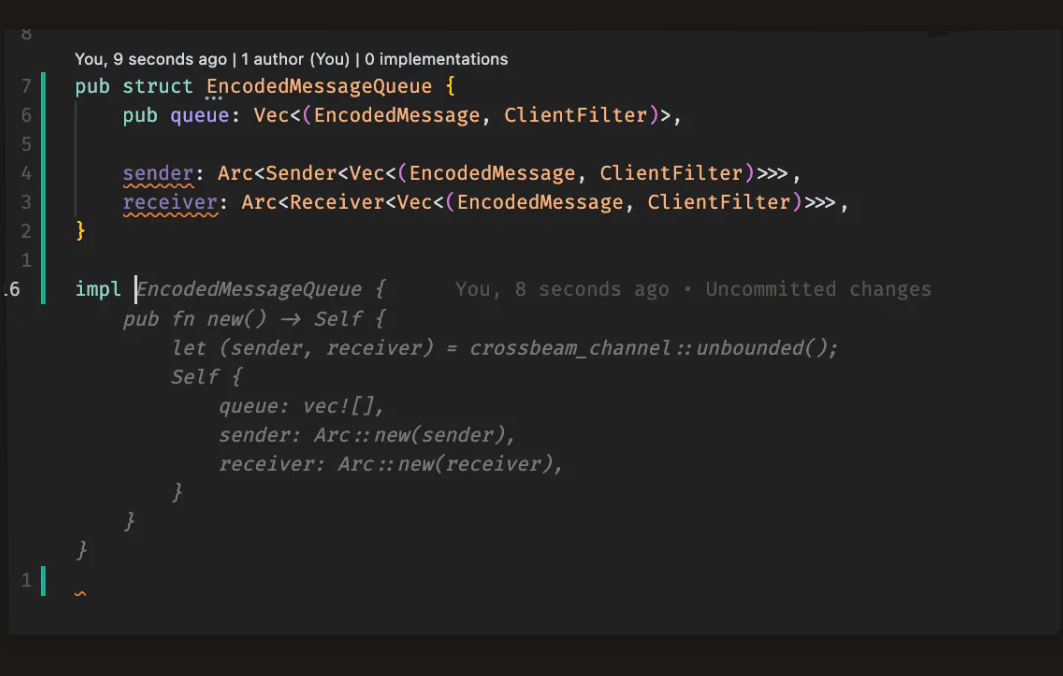
Image of Tab suggestion
Tab is a Cursor model built for smart autocompletion. It learns from your choices — accept with Tab, reject with Esc — so suggestions get better over time. With Tab, you can:
- Edit multiple lines at once
- Auto-add missing imports
- Move across files for coordinated changes
- Get context-aware suggestions based on recent edits and linter feedback
Tab is one of the early features that helped Cursor gain traction but overtime newer features like Chat mode and Cmd+K got more usage.
Cmd + K
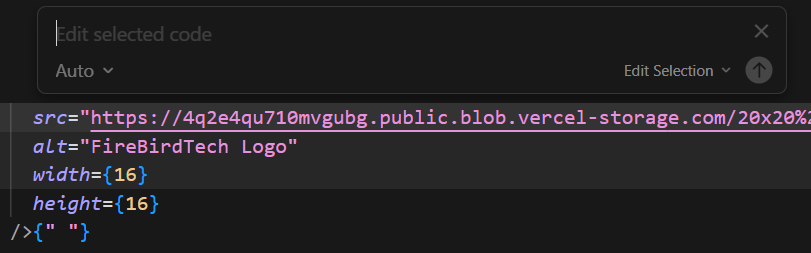
Image of Cmd+K menu
Cmd + K allows you to select a piece of code or a file and request cursor to make quick changes.
Chat

Taken from Cursor docs
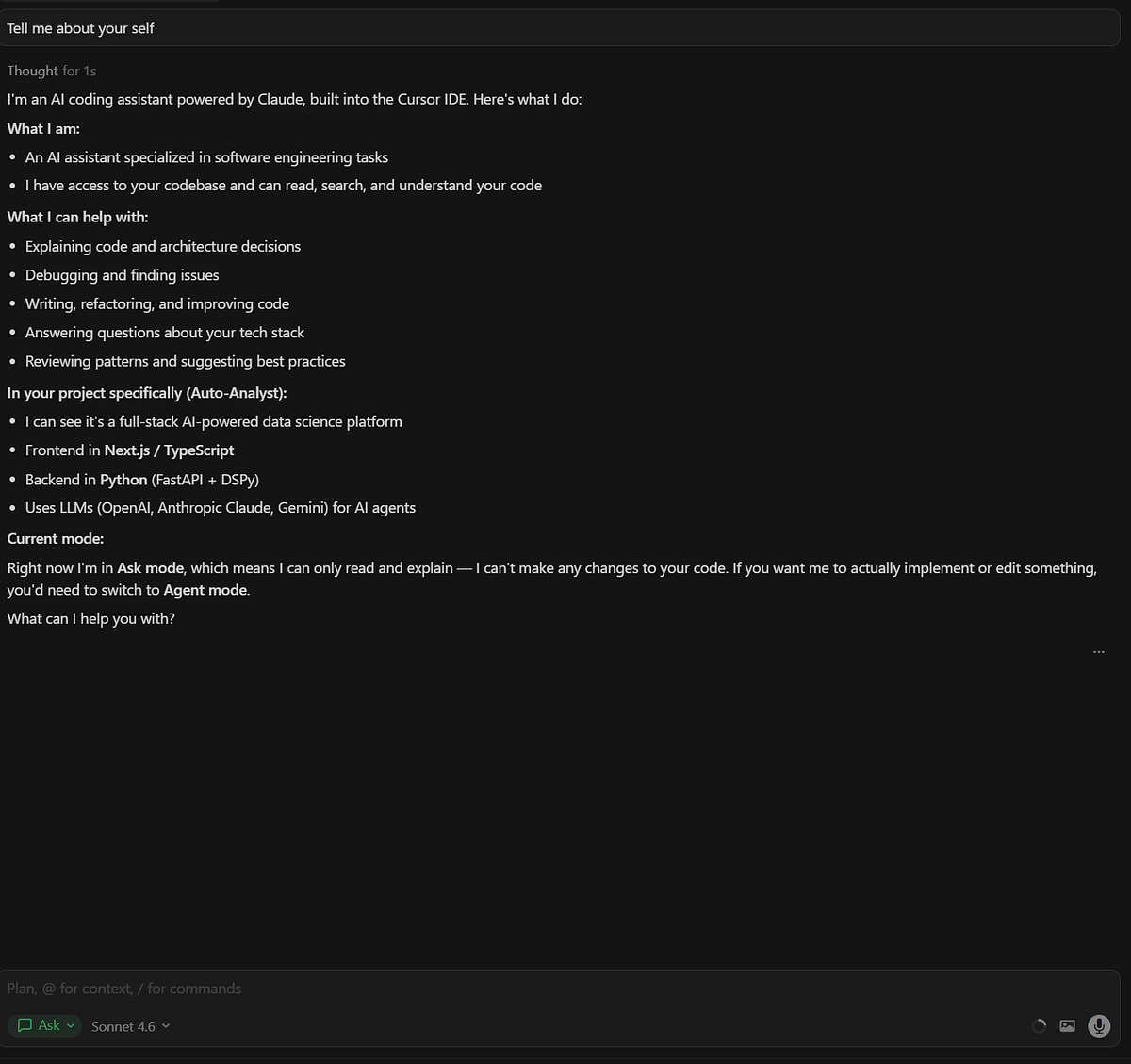
An example of the Agent/Chat window
In the chat module, you’ve got 4 ways to interact:
- Ask — Get answers or explanations without changing your files.
- Plan — Maps out a full plan of changes, including a
.mdfile and next steps. - Agent — Acts directly on your request.
- Debug — Dives into errors using logs like a debug pro.
Now that we know what Cursor can do, let’s jump into the review challenge.
Review Challenge
In all my coding platform reviews, I have the system replicate one of my projects. For this challenge, I’ll prompt Cursor in an empty folder to replicate autoanalyst.ai.
We’ll use Composer 1.5 here — a unique model/agent exclusive to Cursor. If I went with Opus 4.6, people will argue that the heavy lifting is by Anthropic engineers not Cursor engineers/makers itself.

This is the exact prompt I used in mylovable review
Options Cursor asked in the prompt
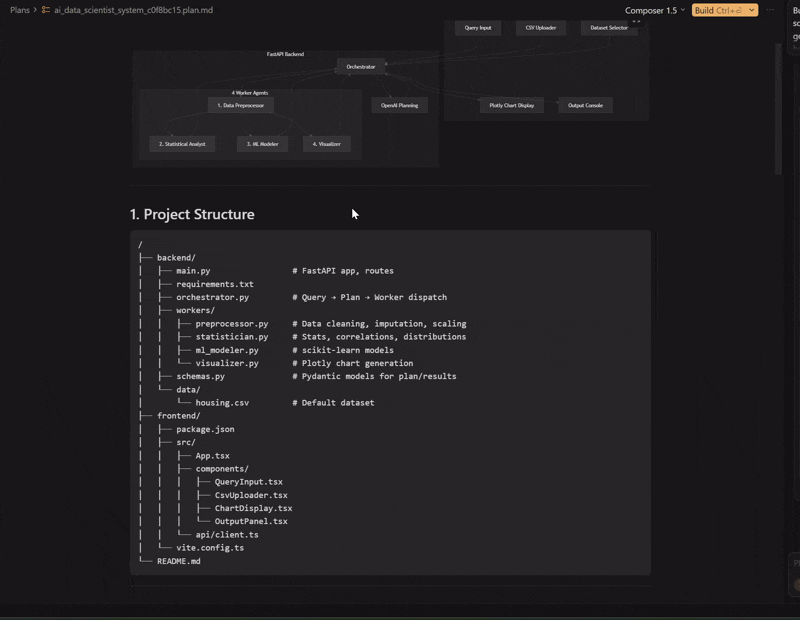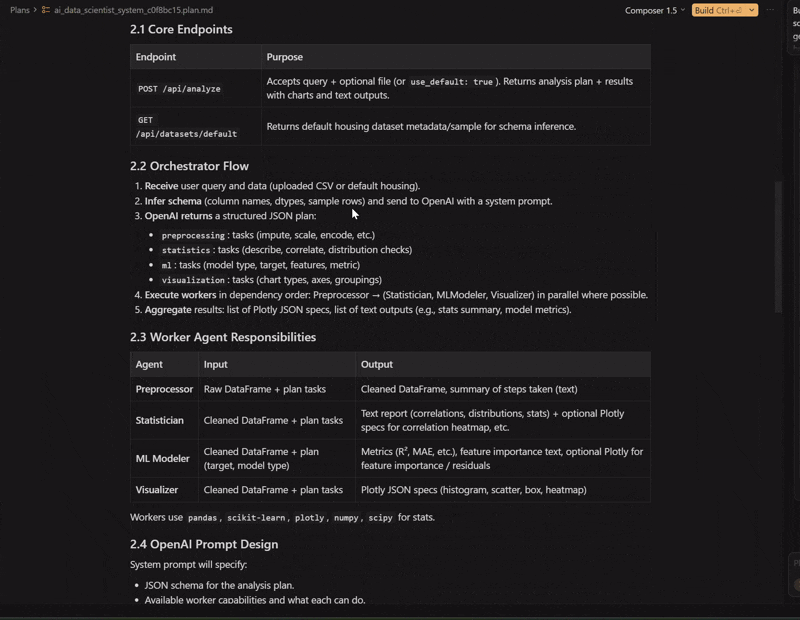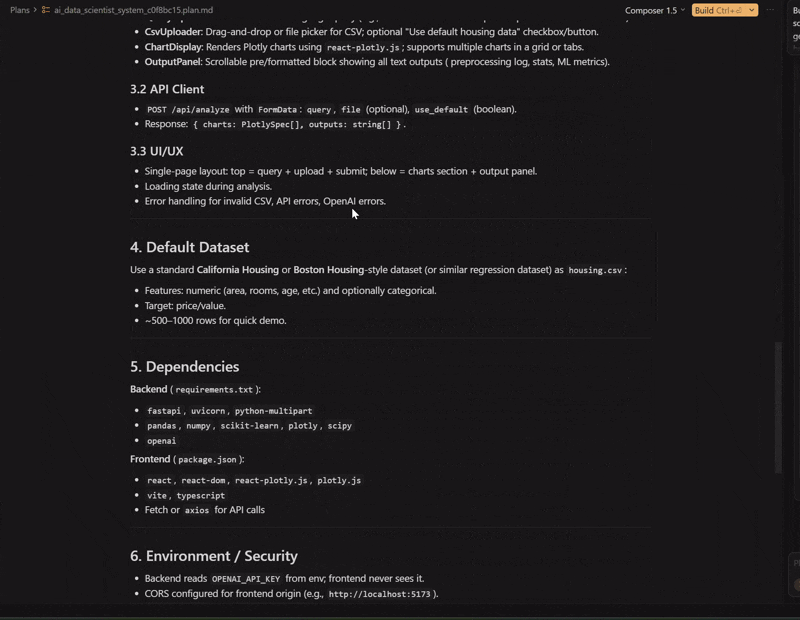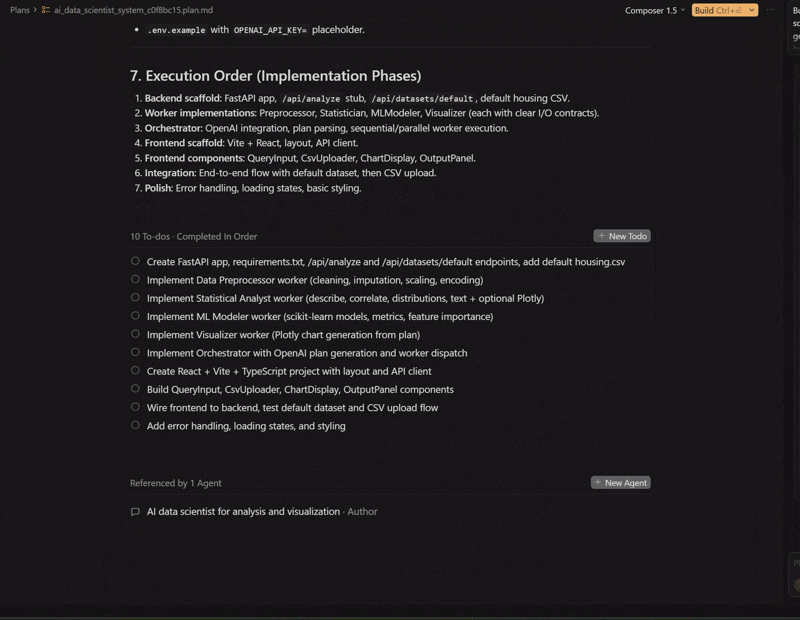
The walkthrough of the plan it built
Cursor agent creating the system
The implementation summary, after zero interventions
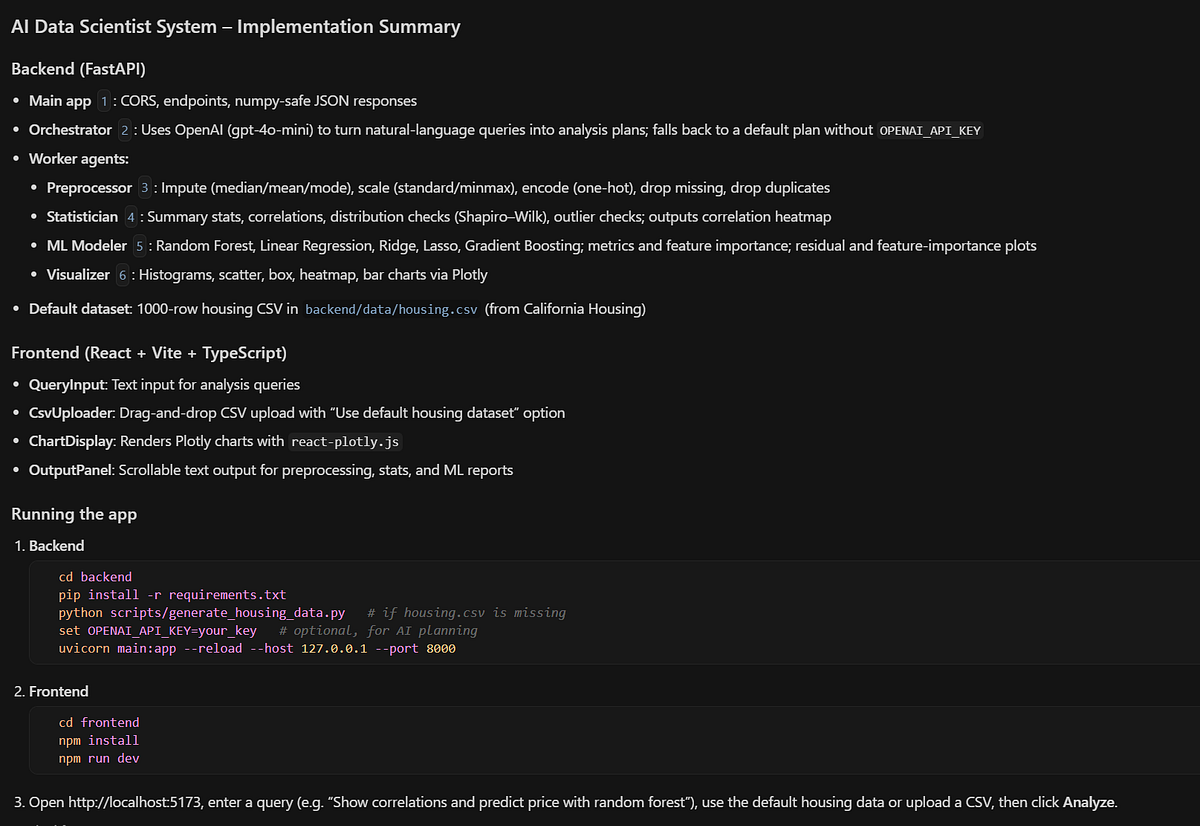
Cursor explaining what it built
Now lets try out what it
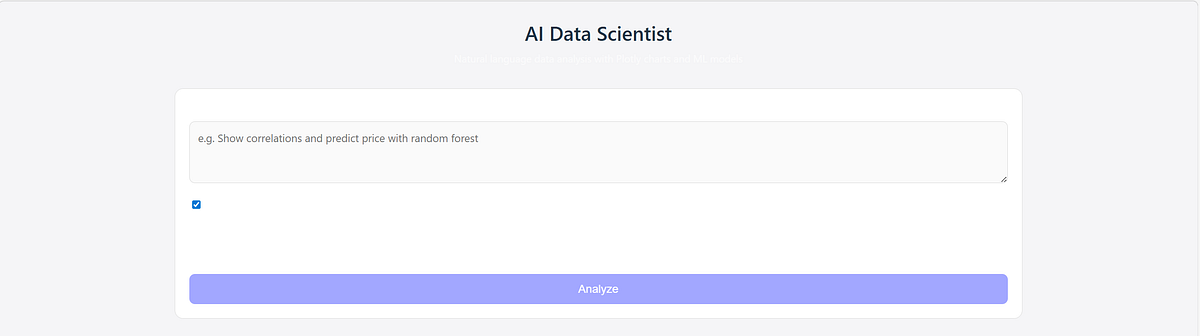
This is the UI which obviously isn’t bery good.
Want both the speed of vibe-coding & the trust/reliability of actual software engineer? Hire me & my team for your next project. We have built over 20+ app, many in production for startups, $Bn companies & academics.
Reach out here: https://tally.so/r/3x9bgo
I asked it to visualize the data and tell me which houses (sample data is of housing) are important.
This is what it built in one shot
Initial Thoughts
- UI Experience: The user interface was not very well-designed or aesthetically pleasing.
- Functionality & Cost: Despite the UI issues, the system functions reliably. Compared to other platforms for “vibe coding,” it is relatively affordable — unless you go beyond the Pro plan limits.
- One-Shot Use: For single, focused tasks using their Composer model (which offers higher usage limits than Opus/Codex), it serves as a solid starting point.
Things I like about Cursor:
- Model Optionality: Cursor offers a variety of models, including its own Composer model. This flexibility is a major reason I remain a long-term supporter. By contrast, switching to Claude Code would lock me into only Anthropic’s models.
- Good UX: The Cursor team was among the first to nail a user-friendly experience for coding agents. Features like Tab autocomplete and Cmd+K made the tool feel engineered by developers for developers.
- Speed & Familiarity: The system is generally fast and responsive, though performance varies by model. Choosing VSCode as the interface foundation was smart — most software engineers are already familiar with its workflow, reducing friction and improving productivity.
Thing I don’t like about Cursor:
- Aggressive Pricing: Cursor is affordable only if you remain within the pro-plan limits, afterwards the costs scale quickly. I can understand why since they don’t own the model APIs they have to charge a premium. The number one complaint on r/Cursor is usually about how quickly costs scale after plan limits reached.
- Unreliable Context switching: In my own use I found that the chat module does not switch context reliably enough. If I asked it to move from feature A to feature B it sometimes starts making changes again to feature A.
- Auto model selection is useless: Auto is suppose to give you balanced model to get your tasks done. However, I almost never use it after trying it once or twice. Almost all changes by auto are not very good or balanced.
Cursor Wishlist:
- Top tier Composer Model: Composer is good when you know what you are doing. However, it can’t compete with latest models made by Anthropic/OpenAI. I really wish they build the top tier competitor to gpt and opus.
- Better UI builder: Depending on when you read this, they might have already fixed this. However, mostly the UI built by cursor is similar, it usually has that ‘made with AI’ feel. If they can ensure that their orchestrator can make a ‘different’ UI than most, it would be awesome.
Overall, cursor is a great tool. One me & my team use every day. I hope you enjoyed this review, please follow & subscribe
Want both the speed of vibe-coding & the trust/reliability of actual software engineer? Hire me & my team for your next project. We have built over 20+ app, many in production for startups, $Bn companies & academics.
Reach out here: https://tally.so/r/3x9bgo
Honest review of Lovable from an AI engineerI tried lovable to build projects, and here is an honest reviewwww.firebird-technologies.com
Need help shipping AI products?
FireBird Technologies builds custom AI agents, internal analytics, and full SaaS products for teams that want to move fast without compromising on quality. If anything in this post sparked an idea, we'd love to hear about it.
Originally published on FireBirdTech Substack.